Warum das Entity Framework für Domain-Driven Design nicht geeignet ist
Ausgangssituation
In der aktuellen Ausgabe des Fachmagazins Visual Studio One ist der vierte Teil meiner Windows Azure Kolumne erschienen. Thematisch geht es um SQL Azure. Im Artikel geht es darum, dass Objektmodell der vorherigen Ausgabe an eine SQL Azure Datenbank anzubinden. Wie schon oft habe ich dabei auch das Thema O/R Mapper andiskutiert. Natürlich habe ich das Thema in den Kontext von Domain-Driven Design gesetzt. Ich habe angekündigt, in einem kritischen Blogbeitrag ausführlicher meine Sichtweise zum Einsatz des Entity Frameworks mit DDD-Ansätzen aufzuzeigen. Den Beitrag habe ich nun schon eine Weile in der Schublade, das heißt als Entwurf in WordPress J. Es ist an der Zeit, diesen nun zu vollenden und vorzustellen.
Häufig wird der Graben zwischen Objektmodell und der relationalen Datenbank als groß beschrieben, meistens eben auch als Problem. Schnell wird dann zu einem O/R Mapper gegriffen und damit sollte das Problem gelöst sein. Doch ist das wirklich so? Ich habe mich in den letzten Jahren in vielen verschiedenen Projekten mit der Thematik auseinandergesetzt und versucht, brauchbare und pragmatische Lösungen zu finden. In vielen Projekten ging es um die Erstellung von Unternehmenslösungen mit umfangreichen, komplexen Geschäftsprozessen. So habe ich vor ca. 5 Jahren begonnen, mich mit Domain-Driven Design zu beschäftigen und Wege der Anwendung dieser Prinzipien in Softwareprojekten im .NET Umfeld zu finden. …und dieser Weg war sehr steinig. Viele Erkenntnisse mussten hart erarbeitet werden. Domain-Driven Design ist inzwischen etwas zum Modewort geworden und wird manchmal leider fälschlich verwendet. Es existieren inzwischen auch sogenannte DDD Light Ansätze, die im Wesentlichen die technischen Aspekte von DDD verwenden.
In Projekten kommt sehr häufig die Frage auf: „Wie mappen wir unser Objektmodell auf die Datenbank?“ Schnell wird dann zu einem O/R Mapper gegriffen und Objekte aus den vorhandenen Datenbanktabellen erzeugt, im Glauben dann ein Domänenmodell zu besitzen. Nur ist das leider nicht der Fall. Entitäten im Sinne von DDD sind etwas anderes als Datenbank-Entitäten. Entitäten im DDD-Ansatz sind Domänenobjekte, die aus Verhalten und Struktur bestehen. Entitäten der Datenbank bestehen nur aus Struktur und natürlich Beziehungen zu anderen Objekten.
Die Mängel des Code First Ansatzes
Mit dem Entity Framework ist es seit einigen Versionen möglich, den Code-First Ansatz zu verfolgen. Dieser erlaubt es, Objekte mit Struktur und Verhalten zu modellieren und daraus Datenbanktabellen erzeugen zu lassen. Ich habe mich schon einige Male in Evaluationen mit diesem Vorgehen beschäftigt und kann mir nicht vorstellen, dass dieser Einsatz für echte Projekte und vor allem in Hinblick auf eine optimale Datenbankstruktur wirklich taugt. Das soll aber nicht Schwerpunkt dieser Ausgabe sein. Ich werde diese Diskussion zu einem späteren Zeitpunkt nochmals aufnehmen.
In dieser Ausgabe möchte ich eher auf die Probleme eingehen, die im Hinblick auf objektorientierte Prinzipien codeseitig entstehen.
Stellen wir uns vor, wir müssten das Domänenobjekt Ente mit verschiedenen Methoden (Verhalten) und Eigenschaften (Struktur) modellieren. Es muss möglich sein, sicher und konsistent neue Objekte zu erzeugen. Die Anforderung besteht darin, dass die Ente (Objektinstanz) eindeutig zu identifizieren ist (ID), einen Namen hat und durch eine Farbe charakterisiert ist. Die Ente soll fliegen können und jeder Flug soll gespeichert werden und über eine Liste der Flüge einsehbar sein. Dies bedeutet, es muss eine Möglichkeit bestehen, die Flüge zu sammeln und zu persistieren. Beim Erstellen einer neuen Objektinstanz soll eine Regel, nämlich die maximale Ausflugsstrecke in Kilometer festgelegt werden. Dieser Wert ist unveränderbar solange die Ente existiert, was bedeutet, dass der Wert nur bei der Erstellung (Anlegen) einer neuen Instanz benötigt wird, persistiert werden soll und dann nur intern in der Klasse selbst verwendet wird, um eine Validierung der Flugstrecke beim Aufruf der Methode „Fliegen“ vorzunehmen. Die Liste der Flüge darf im Übrigen nicht manipulierbar sein.
Daraus ergibt sich folgender Entwurf unter Einhaltung objektorientierter Prinzipien, Abbildung 1. Auch das in meinem Artikel zu Messaging und Entkoppelung erwähnte Geheimnisprinzip soll wieder Anwendung finden.
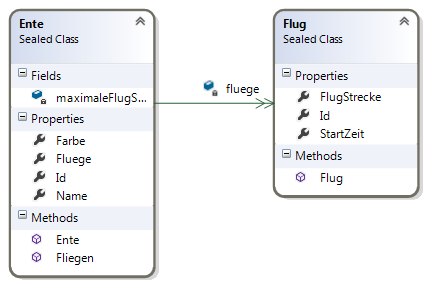
Abbildung 1 – Objektmodell für die Anforderungen
Die Klasse Ente sieht wie folgt aus, Abbildung 2. Der Konstruktor soll der sicheren Erzeugung neuer Objekte dienen und fungiert quasi als Factory. Die Wiederherstellung bereits persistierter Objekte soll dann das Entity Framework übernehmen. Für den Wert der maximal zulässigen Flugstrecke der Ente, verwendete ich ein readonly Feld, da der Wert nur interne Verwendung findet und nach der Erstellung nicht mehr verändert werden darf. Der Wert muss für Client Code nicht sichtbar sein. In Abbildung 3 ist die Klasse Flug zu sehen, die auch eine Factory-Methode (Konstruktor) nutzt, um konsistente Instanzen zu erzeugen.
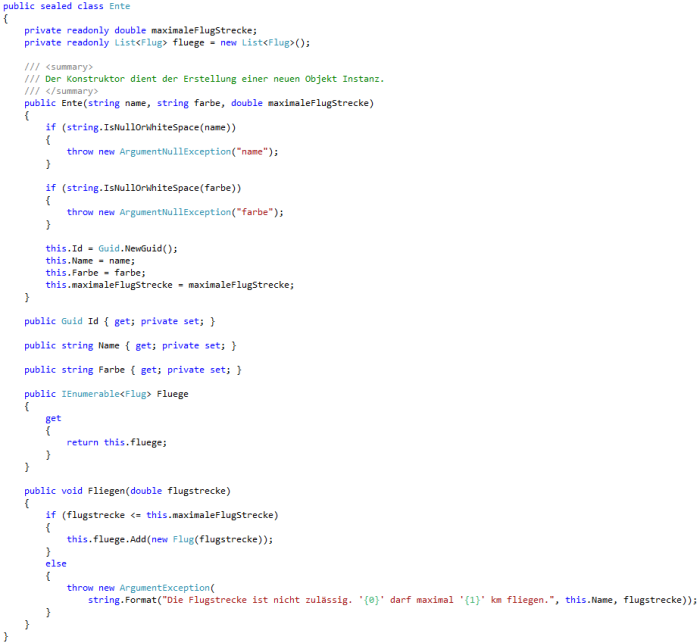
Abbildung 2 Die Klasse Ente erfüllt die Anforderungen.
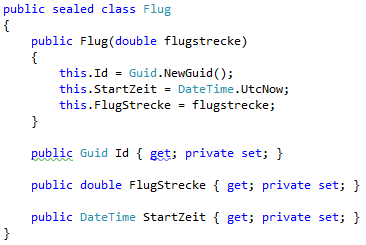
Abbildung 3 Die Klasse Flug.
Soweit so gut. Probieren wir nun den Code aus und schauen, ob sich alles wie gewünscht verhält. Dafür habe ich eine kleine Konsolenanwendung geschrieben, die eine Enteninstanz erstellt und die Ente zwei mal fliegen lässt und dann noch versucht, sie zu überfordern, Abbildung 4 und 5.
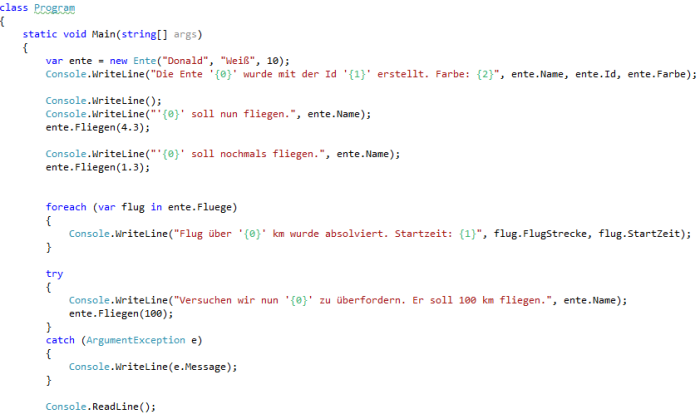
Abbildung 4 Aufrufe über ein kleines Programm
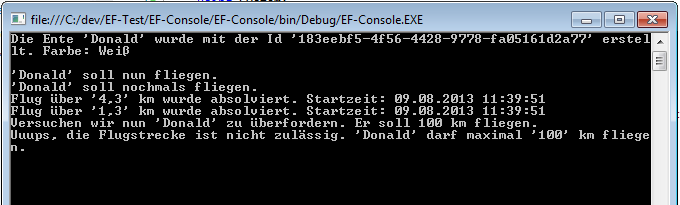
Abbildung 5 Die Ausgabe in der Konsole. Anwendung läuft und die Ente lässt sich nicht überfordern
Bis hierher haben wir objektorientiert gearbeitet und saubere Klassen entworfen. Wir haben uns auch nicht um Persistierung gekümmert, da wir dem Code-First Ansatz folgen. Diese Aufgabe übergeben wir nun dem Entity Framework und schauen uns nun an, was passiert. Dafür müssen wir nur eine Klasse erstellen, die DbContext implementiert, siehe Abbildung 6. Danach wird der DataContext in der Konsole verwendet, Abbildung 7.
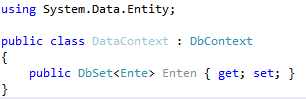
Abbildung 6 Datenkontext hinzugefügt

Abbildung 7 Den Datenkontext nutzen und das Objekt speichern
Das Entity Framework erstellt die Datenbank und Tabellen im Hintergrund, sofern sie noch nicht vorhanden sind. Schauen wir uns das Ergebnis an, Abbildung 8. Es scheint alles zu funktionieren. Der Code sagt, er hätte eine Ente verspeichert. Prüfen wir das nun in der Datenbank.

Abbildung 8 Die Ausgabe verspricht Gutes
Werfen wir einen Blick in das SQL Server Management Studio. Cool, die Datenbank wurde erstellt. Aber: leider nur unvollständig. Das Feld maximaleFlugStrecke als auch die Flugauflistung fehlen, Abbildung 9.
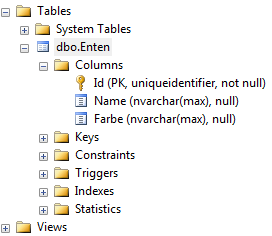
Abbildung 9 Der Blick ins SQL Server Management Studio zeigt das nicht alle Datenfelder und die Referenz auf die Flüge nicht erstellt wurden
Grund dafür ist, dass das Entity Framework nicht in der Lage ist, Felder als Datenbankspalten zu speichern. Leider gibt es auch kein Attribut dafür. Damit kann ich notfalls leben und mache aus dem Feld maximaleFlugStrecke eine Eigenschaft, so dass die Spalte in der Datenbank erstellt wird.
Das zweite Problem finde ich gravierender. Das Entity Framework kann nicht mit einer Auflistung vom Typ IEnumerable<T> umgehen. Auflistungen müssen vom Typ Collection<T> , damit die Tabellenstruktur richtig erstellt wird. Hier wird aber ein grundlegendes Prinzip der Objektorientierung gebrochen. Aber schauen wir uns zunächst an, wie die Klasse Ente verändert werden muss, damit die Datenbank wie erwartet erstellt wird, Abbildung 10.
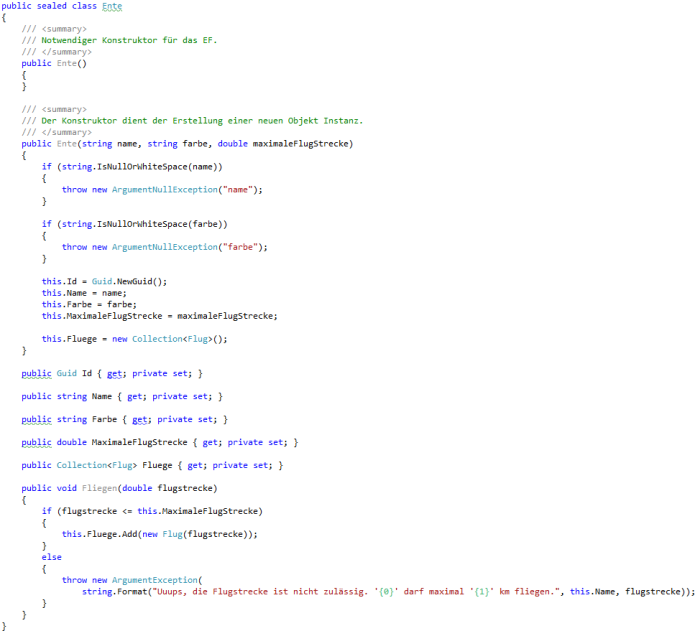
Abbildung 10 Notwendige Änderungen an der Klasse für Code First.
Damit das Entity Framework ein Objekt beim Zurücklesen aus der Datenbank wieder instanzieren kann, wird außerdem noch ein parameterloser Konstruktor benötigt. Der wurde in Abbildung 10 ergänzt. Das gefällt mir gar nicht! Denn: Das Erstellen inkonsistenter Objektinstanz ist nun auch grundsätzlich im Client Code möglich. Der Aufruf new Ente() ist nicht zu verhindern. Oje! Die Anforderung „Es muss möglich sein, neue Objekte sicher und konsistent zu erzeugen“ kann damit nicht mehr erfüllt werden.
[Korrektur, 9.8.2013]
Ein Kollege wies mich soeben darauf hin, dass man die für das EF erforderlichen parameterlosen Konstruktoren auch „private“ machen kann. Dann sieht das doch schon besser aus. 🙂 Die inkonsistente Erzeugung neuer Objekte ist damit nicht möglich. (Pluspunkt)
Die private List<Flug> und die öffentliche Auflistung IEnumerable<Flug> wurden entfernt und dafür eine öffentliche Collection<Flug> erstellt. MaximaleFlugStrecke ist nun eine öffentliche Eigenschaft. Die Erstellung der Tabellen in der Datenbank klappt damit reibungslos. Das Ergebnis ist wie erwartet, Abbildung 11.
Abbildung 11 Datenbank wurde wie erwartet erstellt
Das Problem
Welches Problem ergibt sich aber nun aus der geänderten Implementierung aus Abbildung 10?
Änderungen an Daten eines Objektes sollen nur über definierte Schnittstellen möglich sein (Geheimnisprinzip). Die Auflistung der getätigten Flüge darf laut Anforderung nicht manipulierbar sein. Um die Bedürfnisse eines Frameworks zu befriedigen, bin ich gezwungen objektorientierte Prinzipien zu brechen und kann Anforderungen nicht erfüllen. Die Liste der Flüge ist nun für Client-Code (siehe Abbildung 12) ohne weiteres manipulierbar. Ich kann nicht verhindern, dass ein Konsument der Klasse auf der Flüge-Collection Clear() aufruft und die Liste damit leert und speichert.

Abbildung 12 Es entstehen nun ungeahnte und ungewollte Möglichkeiten im Client Code
Öffentliche Auflistungen müssen aus meiner Sicht zwingend vom Typ IEnumerable<T> sein, damit Client-Code die Liste nicht selbstständig ändern kann. Sind Änderungen notwendig, so muss die Klasse entsprechende Methoden anbieten. Nur wegen eines Frameworks dieses Paradigma zu brechen, halte ich für absolut inakzeptabel.
Von soliden, objektorientierten Code haben wir uns mit dem Umbau in Abbildung 10 in jedem Fallen sehr weit entfernt.
Fazit und Ausblick
Ich glaube nicht, dass O/R Mapper im Zusammenhang mit Domain-Driven Design/ Objektorientierung das richtige Mittel der Wahl sind. Man sollte den Sinn eines Einsatz in Abhängigkeit von den Anforderungen genau prüfen. Pauschale Entscheidungen zugunsten oder auch dagegen halte ich für suboptimal. Generell halte ich die Verwendung des Code-First Ansatz dann für geeignet, wenn eine optimierte Datenbankstruktur nicht nötig ist und Anwendungen nur eine geringe Komplexität aufweisen. Ggf. genügen aber für solche Einsatzzwecke auch leichtgewichtigere DataTables. Objektorientierung Out-Of-The-Box sind mit O/R Mappern ohnehin nicht möglich, sondern eher das Gegenteil.
Im zweiten Teil der Reihe werde ich darauf eingehen, warum aus meiner Sicht das Problem die objektorientierte und die relationale Welt in Einklang zu bringen, nicht wirklich, sondern nur in unseren Köpfen, existiert.


















